Amazon Personalizeは機械学習によって、ユーザーの購入や視聴などの履歴、年齢、場所などのユーザーに関する情報などを学習します。学習した結果から、各ユーザーにおすすめのアイテムを取得することができます。
この記事では、Amazon Personalizeの使い方を簡単に紹介します!
目次
トレーニングデータを用意する
まずは機械学習のモデルのトレーニングに使用するデータを用意します。
CSVファイルの取得
今回の記事では、映画のレーティングデータを学習させてみます。映画のレーティングデータはMovieLensからダウンロードすることができます。いろいろなフォーマットのデータがダウンロード可能ですが、ここでは”ml-20m”というデータセットを使うことにします。zipファイルをダウンロードして解凍すると、”ratings.csv”というファイルがあると思います。このファイルは、どのユーザーがどの映画にどのくらいのレートをつけたかを集めたものです。
headコマンドでファイルの内容を確認してみます。先頭の10行を表示してみました。
$ head ratings.csv
userId,movieId,rating,timestamp
1,2,3.5,1112486027
1,29,3.5,1112484676
1,32,3.5,1112484819
1,47,3.5,1112484727
1,50,3.5,1112484580
1,112,3.5,1094785740
1,151,4.0,1094785734
1,223,4.0,1112485573
1,253,4.0,1112484940
このファイルの内容から、ユーザーIDが1のユーザーが映画IDが2の映画の評価を3.5としたことがわかります。
データの抽出
次にデータセットの中からレーティングが4.0以上のものを10,000件ランダムに抽出してみます。PythonのライブラリPndasとscikit-learnを使うことで、データ処理を簡単に行うことができます。Pythonのサンプルコードを示します。
コード4行目で”ratings.csv”を読み込んでいます。5行目でデータをランダムに並び替えて、6行目でレーティングが4.0以上のデータを抽出しています。8行目で最初の10,000件のデータを取得、10行目で”ratings_processed.csv”というファイルに出力しています。
1 2 3 4 5 6 7 8 9 10 | import pandas from sklearn.utils import shuffle ratings = pandas.read_csv('ratings.csv') ratings = shuffle(ratings) ratings = ratings[ratings['rating']>=4.0] ratings = ratings.drop(columns='rating') ratings = ratings[:10000] ratings.columns = ['USER_ID', 'ITEM_ID', 'TIMESTAMP'] ratings.to_csv('ratings_processed.csv', index=False) |
S3へのアップロードとバケットポリシーの設定
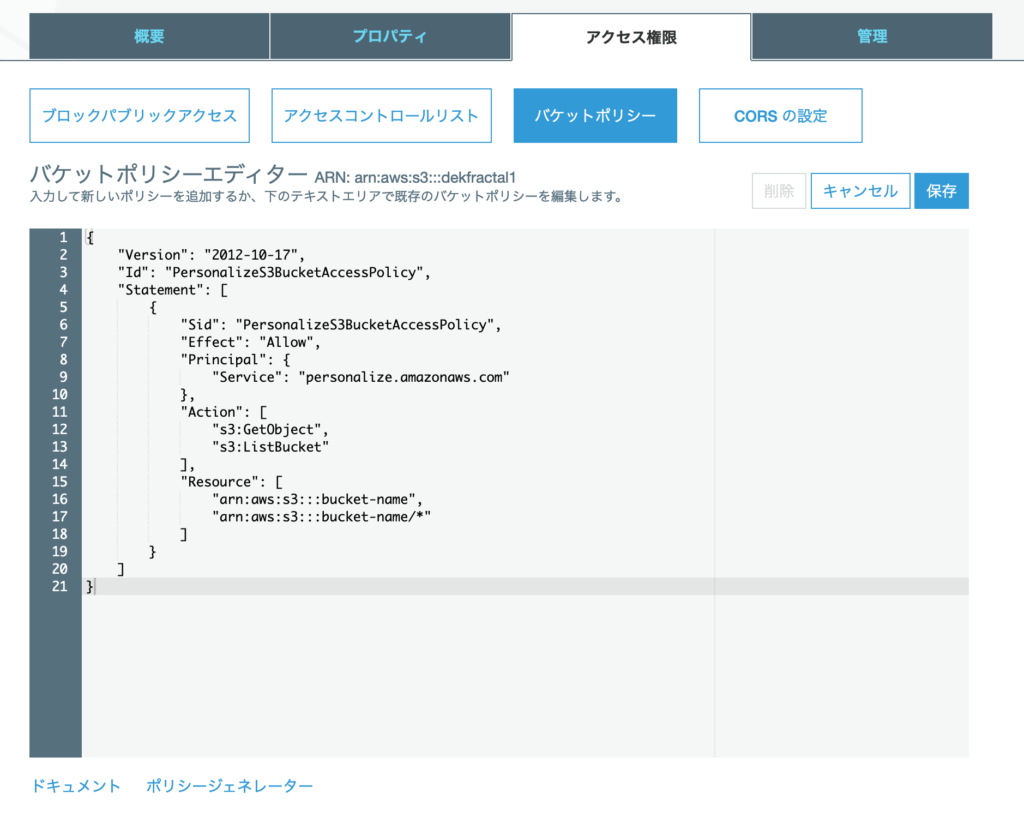
作成したCSVファイルはS3にアップロードしておきます。Amazon Personalizeでは、バケットにアップロードしたデータをインポートします。このため、Amazon PersonalizeからAmazon S3バケットへのアクセス許可が必要となります。次の画像に示すように、バケットポリーの設定を行いましょう。”bucket-name”となっているところには、実際に使用するバケット名を入力してください。編集が完了したら保存します。
Amazon Personalizeコンソール
Amazon Personalize コンソールにアクセスすると、次のような画面が表示されます。さっそくGet startedをクリックして設定を進めていきましょう。

トレーニングデータのインポート
Get startedをクリックすると次の画面が表示されます。まずデータセットグループを作成します。ここではデータセットグループの名前を入力して、Nextをクリックします。
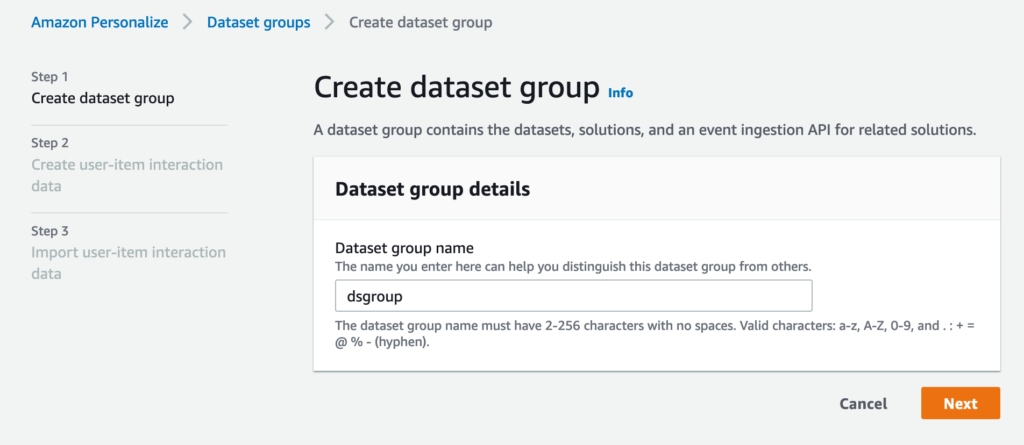
この画面では、まずデータセットの名前を指定します。
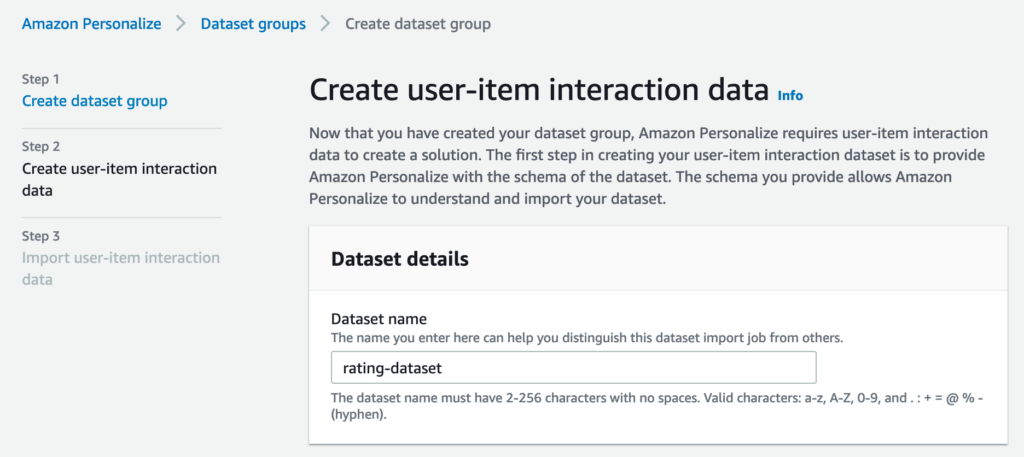
次に、新しく作成するスキーマの名前を指定します。スキーマの定義はデフォルトのままとします。先ほどのPythonのコードで、CSVファイルを出力する前にカラム名を変更しましたが、スキーマのフィールドと同じにするためです。入力と内容の確認が終わったら、Nextをクリックします。
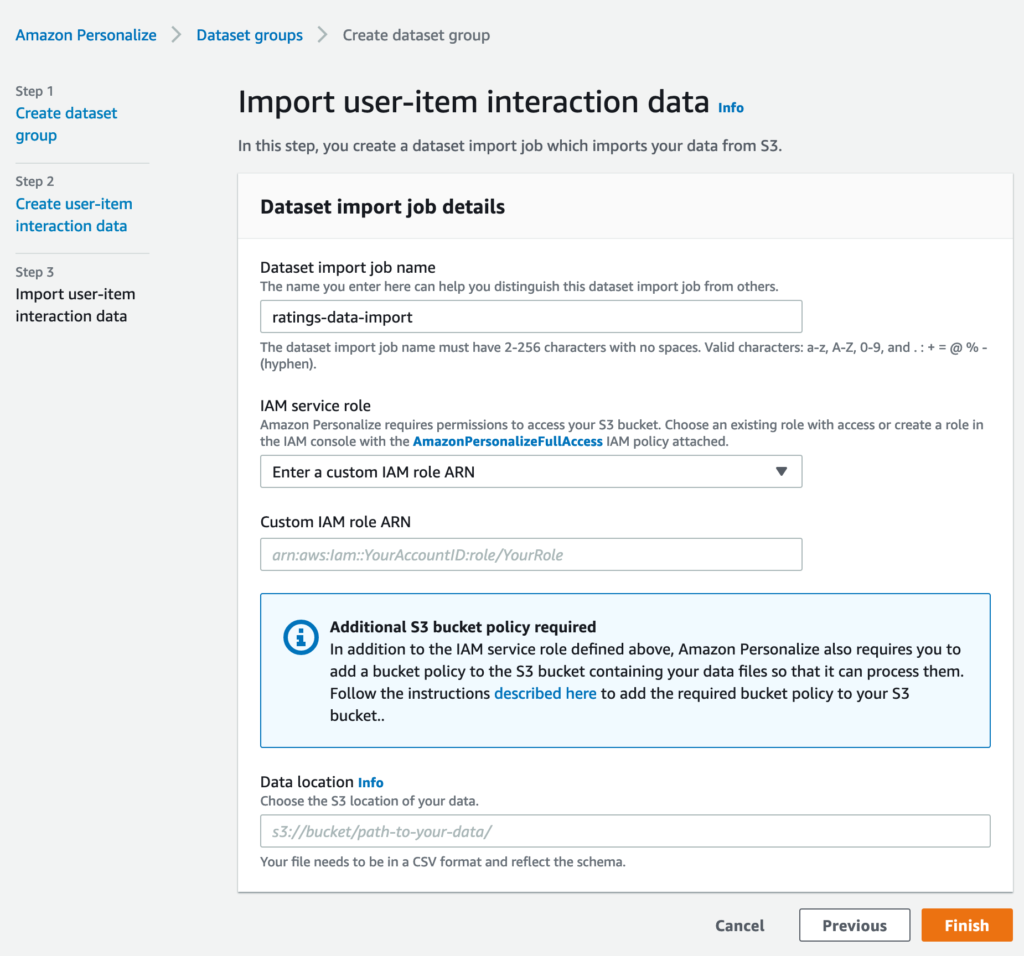
ここではデータセットインポートジョブの名前の指定、IAMロールの作成、読み込みデータの格納場所の指定を行います。
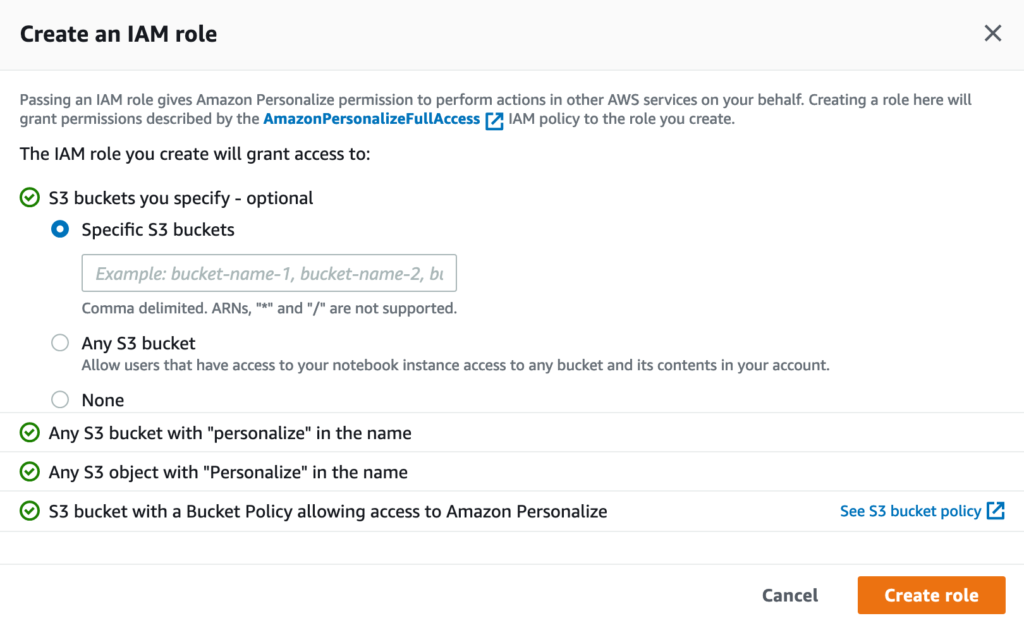
IAM service roleでCreate a new roleを選択すると次の画面が表示されます。CSVファイルが格納されているバケット名を指定して、Create roleをクリックします。
データセットインポートジョブの設定画面に戻りますので、Data locationにCSVファイルの格納場所を指定した後、Start importをクリックしましょう。データのインポートジョブが開始されますので、処理が完了するまで待ちます。
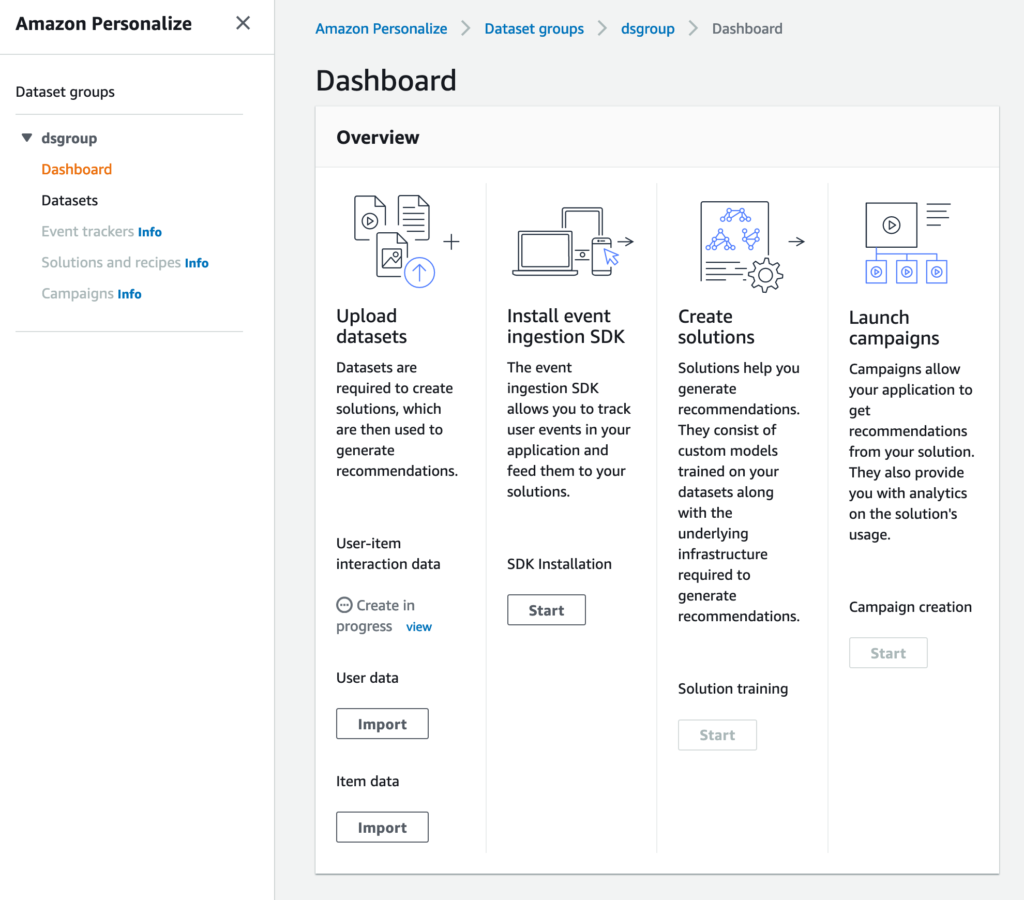
データのインポートジョブが終了すると、User-item interaction dataのステータスがアクティブになります。このとき、Solution creationのStartボタンが有効になっていると思いますので、クリックしてソリューション作成を開始します。

ソリューションの作成
ソリューション作成ページではソリューション名の指定と使用するレシピの選択をします。Recipe selectionでは、Automaticを選択して、デフォルトのレシピリストのままにします。設定が完了したらNextをクリックします。
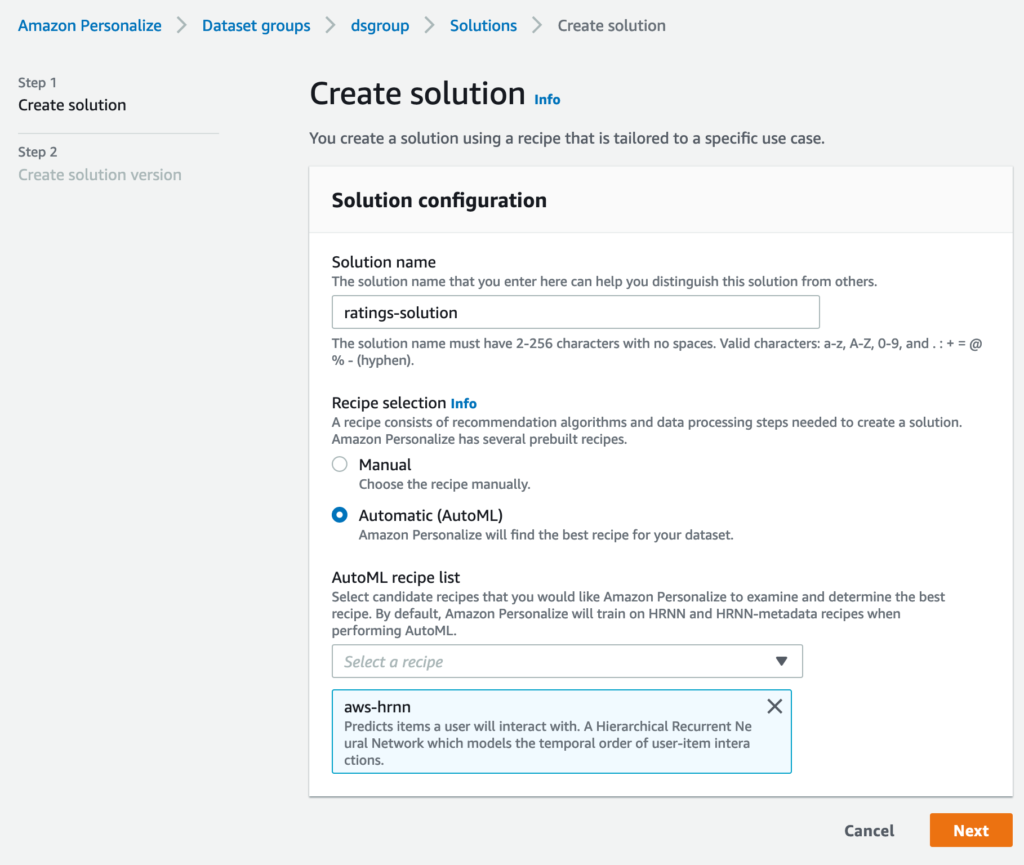
Create solution versionページが表示されると思いますが、デフォルト設定のままFinishをクリックしましょう。ソリューションの作成が開始されますので、処理が完了するまで待ちます。
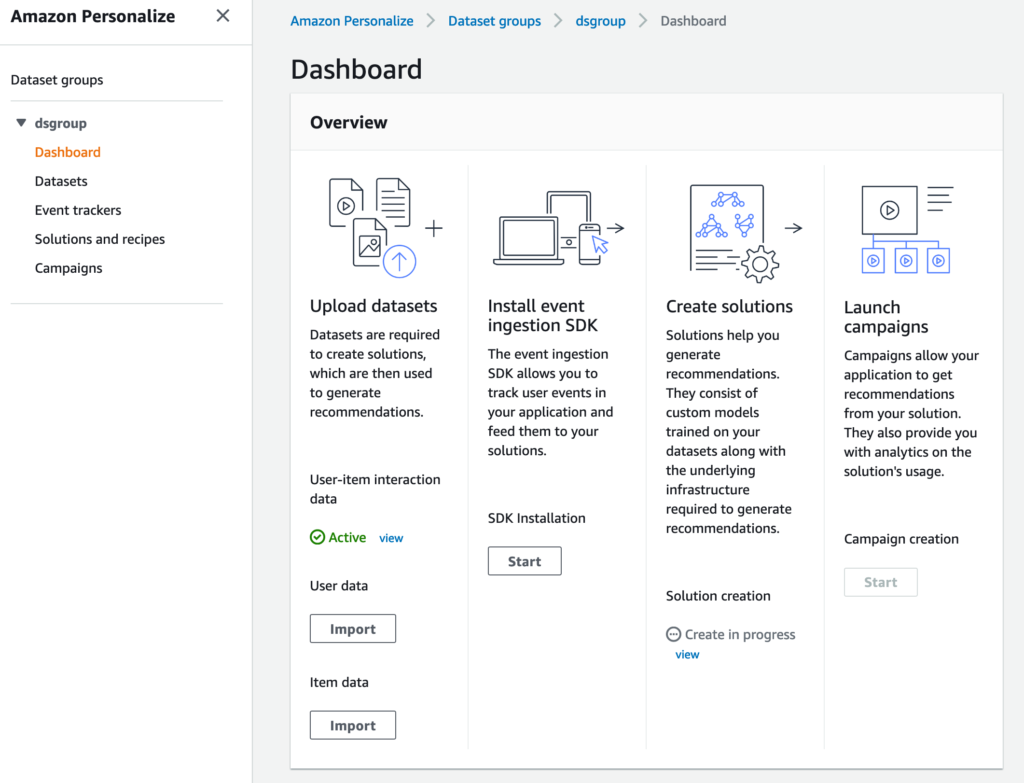
ソリューションの作成が終了すると、ソリューションのステータスがアクティブになります。このとき、Create new campaignボタンが有効になっていると思いますので、クリックしてキャンペーンの作成を開始しましょう。
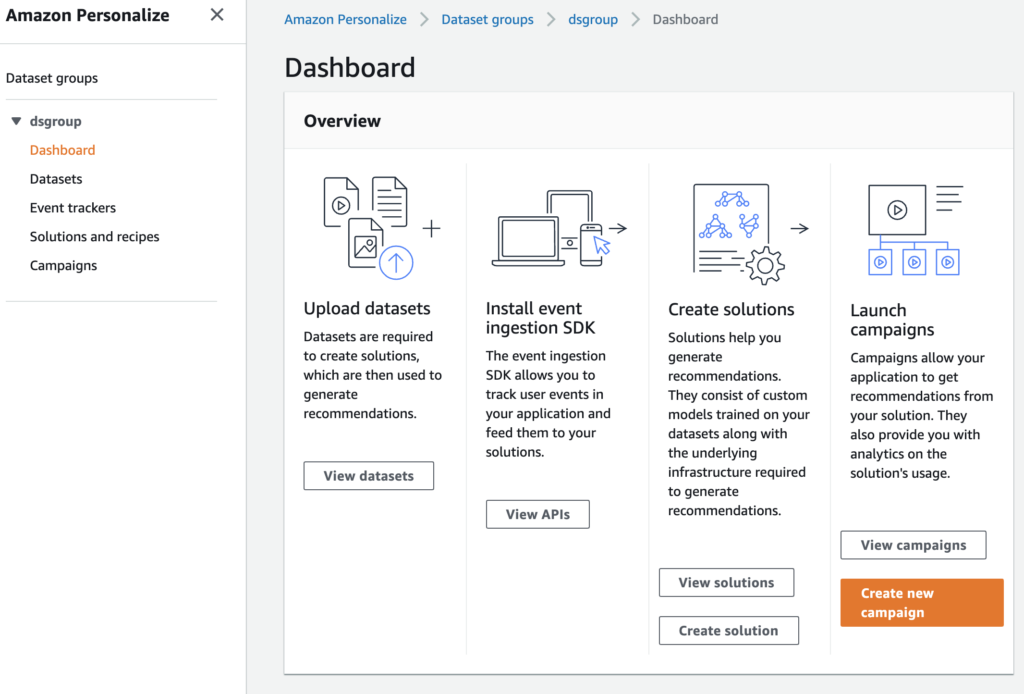
キャンペーンの作成
このページでは、キャンペーンの名前の入力、使用するソリューションの選択をします。Solutionでは先ほど作成したソリューションを選択しましょう。Minimum provisioned transactions per secondはデフォルのままにしておきます。設定が完了したらCreate campaignをクリックして、キャンペーの作成が完了するのを待ちます。
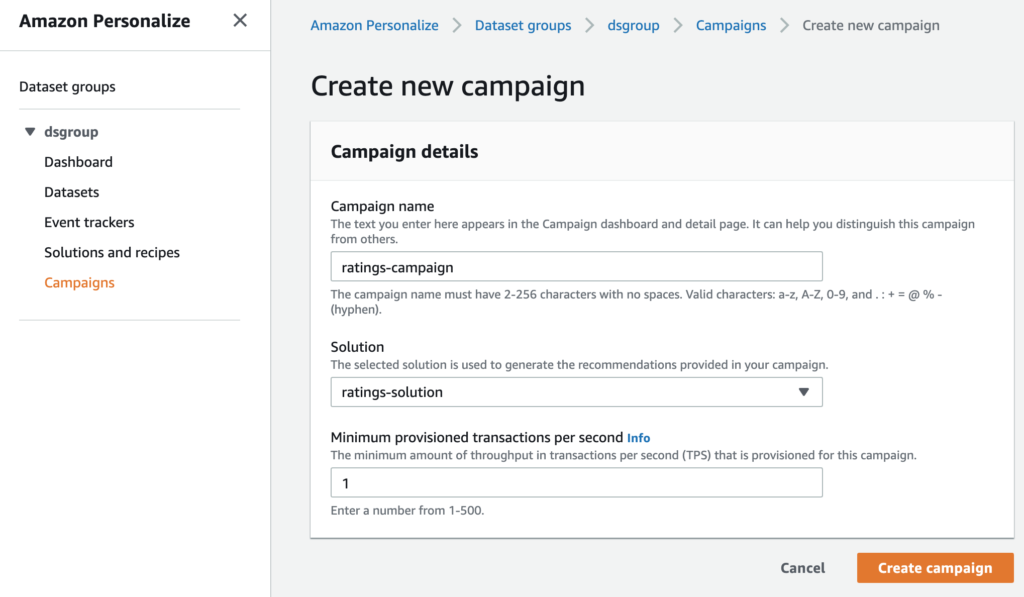
キャンペーンの作成が終了すると、ステータスがアクティブになります。作成したキャンペーンの名前をクリックして次に進みましょう。
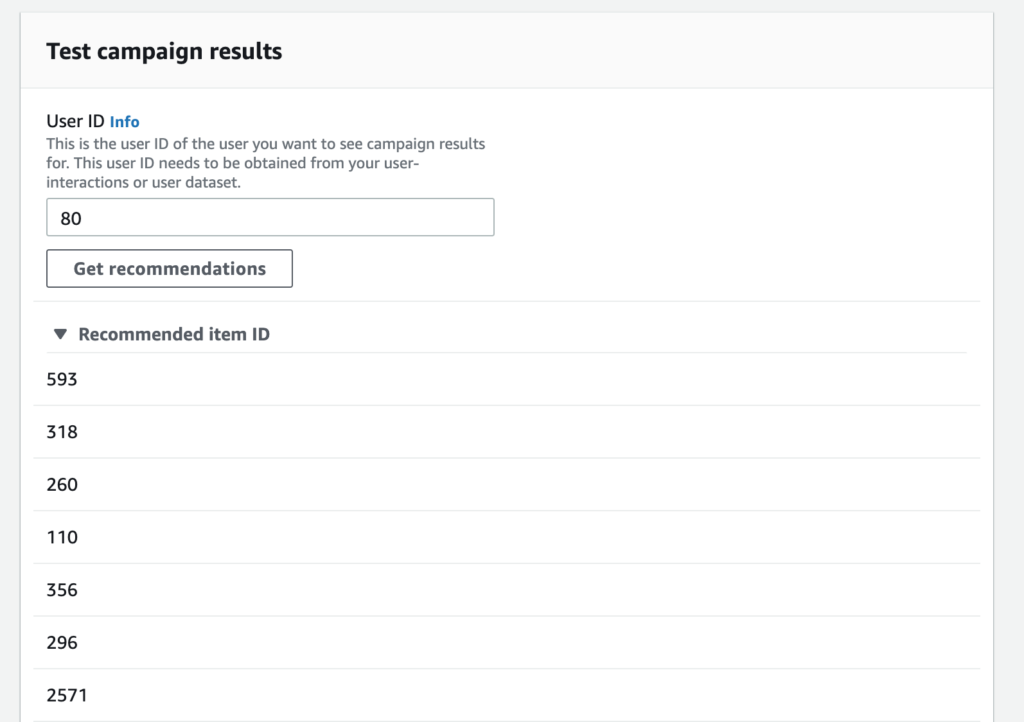
レコメンデーションの取得
このページでは、作成したキャンペーンを使用して、レコメンデーションを取得することができます。User IDに任意のユーザーIDを入力して、Get recommendationsをクリックすると、ユーザーにおすすめの映画ID一覧が表示されます。これで今回の目的が達成されました!
まとめ
今回の記事では、Amazon Personalizeの使い方を簡単に紹介しました!正直なところ、こんなに簡単に学習と結果取得が行えると思っていませんでした。今後も積極的に機械学習に関する記事を書いていこうと思います!!







コメントを残す